Diffusion Models + NLP 杂谈
Exploring the Future of Diffusion Models in NLP
引言
这篇博客用于记录9月-10月的看论文心得,关于Diffusion Model和NLP结合的探索。(当然,11月的我现在觉得几乎完全一种蹭热度的科研废物,毫无意义)不过,还是可以简单探索一下。
所以,本篇博客主要focus在以下四个方面:
- 回顾一些主流的Diffusion Model 和 NLP结合方法
- 介绍更大规模的 diffusion 和 nlp 结合的模型,即参数更多。
- 介绍 diffusion 和 nlp 结合的小众应用方式(文本生成以外)
- Diffusion Model 结合novel的文本生成方法
1. Review
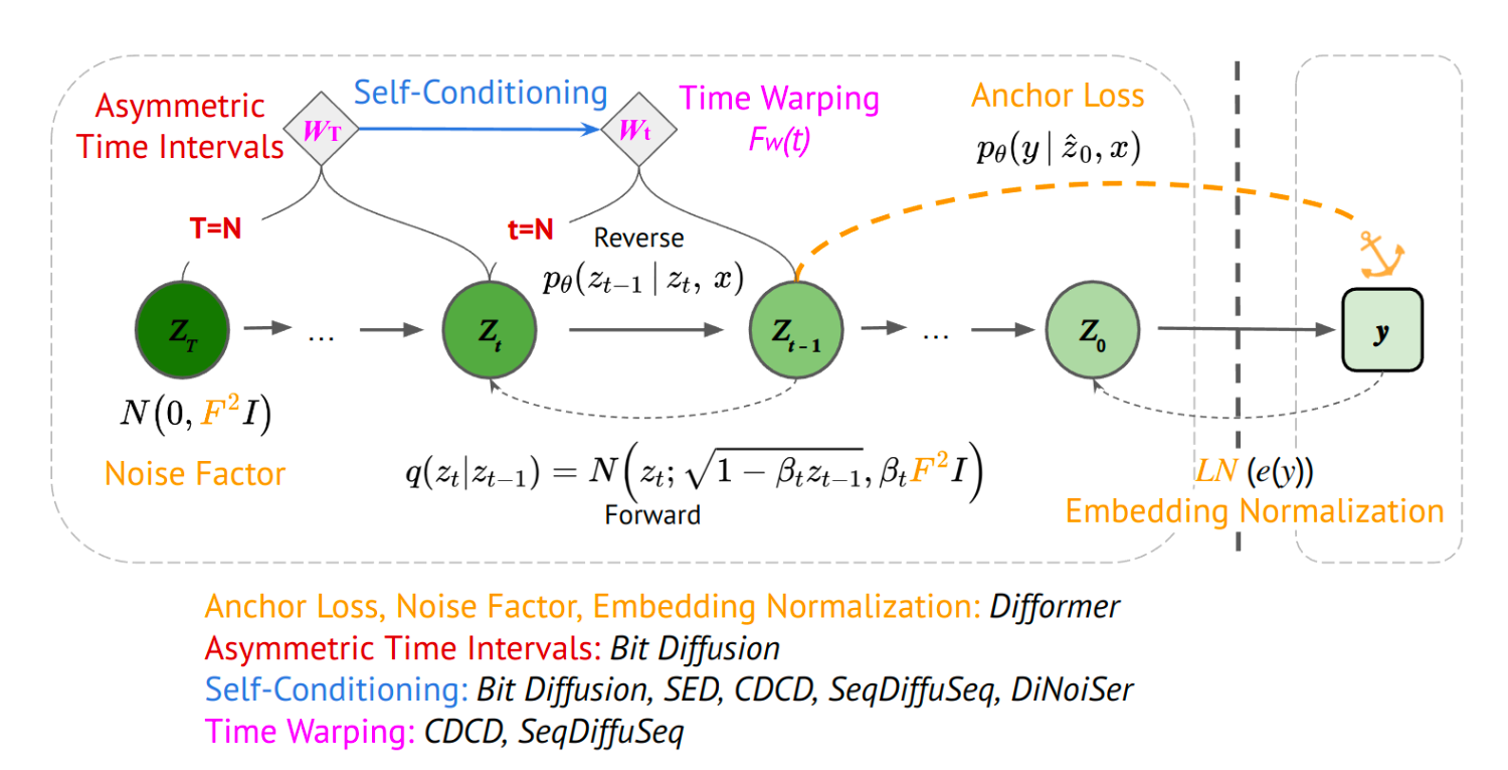
这张图来自今年5月份的survey-A Survey of Diffusion Models in Natural Language Processing。
比如,能提高文本生成性能的方法有self-conditioning等。用在continuous diffusion中的则是图片右半边部份的策略,比如anchor loss也在diffusion-LM中使用了。
除此之外,在检索论文时,也有看过一篇diffusion+NLP的paper,它在别人的模型上加了self-conditioning的方法,就说自己性能提高了比别人好。我个人认为是比较滑水的做法。
2. Scale up the diffusion models in NLP
第一篇 paper :SSD-LM,SSD-LM是2022年10月挂在Arxiv的paper,中了ACL2023。
相关的背景知识
- Diffusion Model,太复杂了,本篇不做详细介绍。
- 自回归语言模型。对于一个 \(w_0\),\(w_1\),到 \(w_{l-1}\) 的长度为 \(L\) 的 sequence ,在自回归语言模型中可以表示为公式4,即当前token是由前面所有token预测得到。
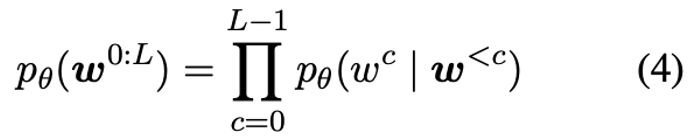
这个模型的 Decoding 的过程同理,是通过 left-to-right 的迭代生成方式。这类自回归模型也有缺点,比如说容易导致句子重复,以及没法自然的融合sequence-level的可控生成。
因此在这篇文章中,作者通过提出了一个半自回归的语言模型,它通过结合 diffusion models 来解决 autoregressive model 的一些问题。
2-1 SSD-LM
Method
在SSD-LM中,diffusion model使用高斯噪声来解码长度为 \(b\) 个tokens的一个块,且以 \(w^{<c}\) 的 tokens 组成序列作为条件。
Training
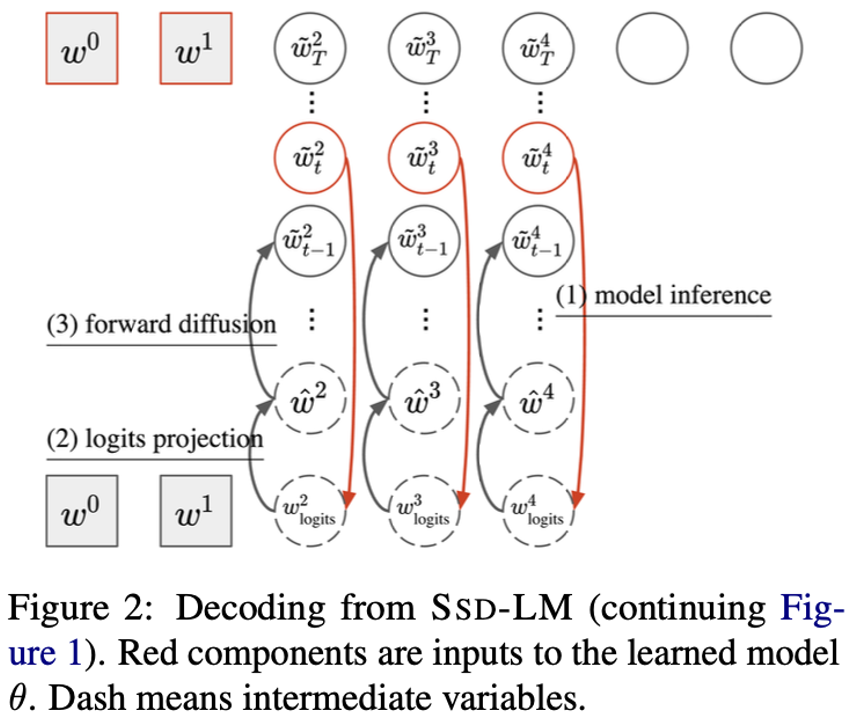
如图所示,前向扩散过程是在某个 token \(w\) 上进行,而不是在全部tokens 上面进行。
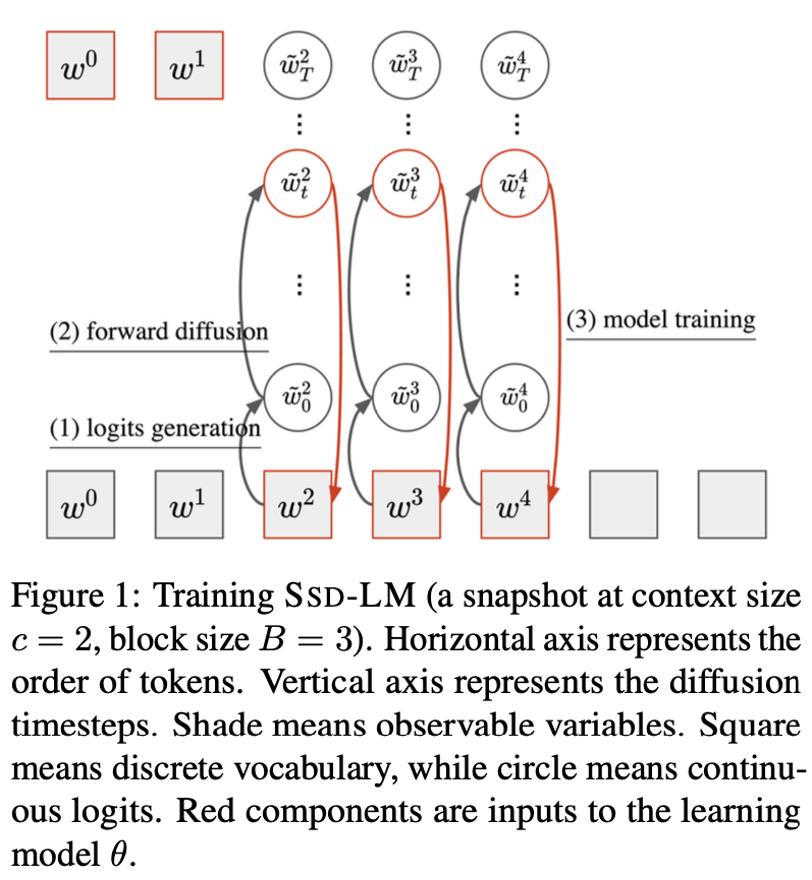
在training的过程中,首先进行mapping,把每个token \(w\) 对应一个维度跟词表大小一样维度的one-hot向量,表示每个单词的对率。
然后使用连续的高斯噪声进行前向扩散过程。loss函数中,也是用了似然来替代l2 distance。
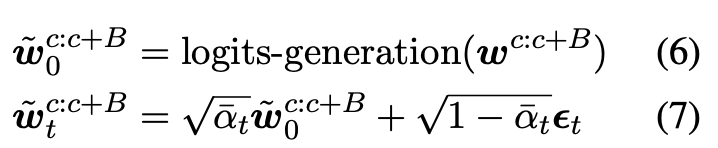
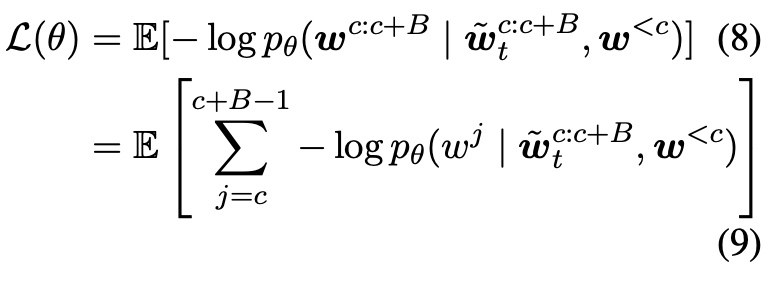
Decoding
在解码过程中,模型使用噪声对率作为输入,并通过预测对率来估计原始token的分布。同时,为了进行逆向diffusion过程,设计一个logits-projection的方式,让预测数据表征接近原始数据表征(almost-one-hot)。
decoding的过程从纯噪声开始采样,并使用第t步计算t-1的值,与一般的reverse diffuson过程相似。
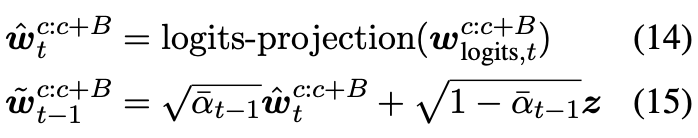
为了生成下一个的block,把当前block连接到之前的blocks以创建一个长度为 c+B 的新上下文,并再次遵循上述反向扩散过程。 重复此过程,直到达到所需的最大长度。
最后是,高度模块化可控的过程,增加了目标方向y,并在梯度更新过程中,让模型靠近classifer的指导。
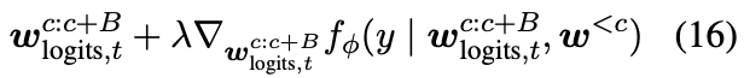
得到的结果如下图所示,可以看出来在一些评价指标上,优于参数量更大的GPT2模型。在可控生成方向,也表现出了较好的可控性。
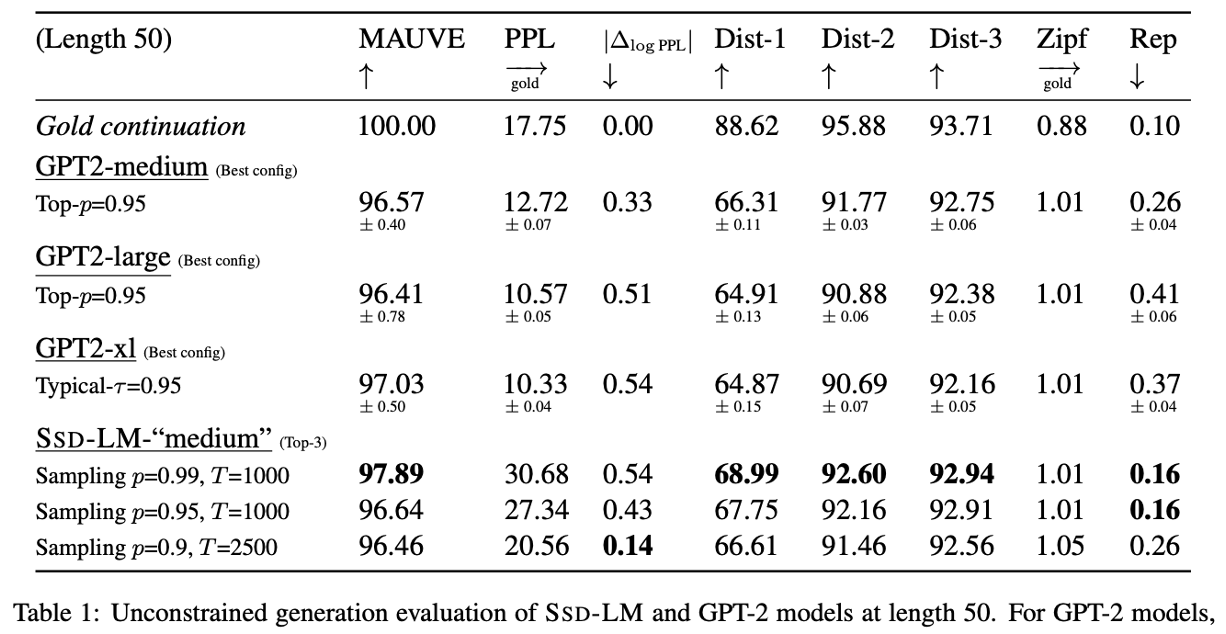
这篇文章在结合了autoregressive language model和non-autoregressive diffusion model的特点。SSD-LM的局限性在于采样效率、解码速度和固定的解码block size。
2-2 SSD-2
因为我最近主要都是在看diffusion nlp结合的文章,我发现大多数文章,都几乎没有与大语言模型进行对比,直到看到了这篇文章,SSD-2,这篇文章是今年5月发表的,在GPT-4提出来之后的。
也是同一个作者,作者的工作是在 MetaAI 工作过程完成的,SSD-2 是base 在SSD-LM模型上开展的。不同之处在于SSD-LM的模型参数只有0.4B,但是SSD-2的模型参数扩大到了13B,虽然远远达不到LLM的参数规模,但是在现有的Diffusion和NLP结合的模型中最大。
相比于SSD-LM模型:
- 0.4B 拓展到 13B 的参数规模。
- 加入了一些(我在review中提到的)skills,比如说self-conditioning。这些skills都能在不同方面提升模型的性能。
- 使用了finetuning的方法,对instruction相关的dataset进行了finetune。作者得出的结论是,对比与Autoregressive模型的baseline,SSD-2的finetune模型效率更好,因为能够更好地利用双向的本文信息。
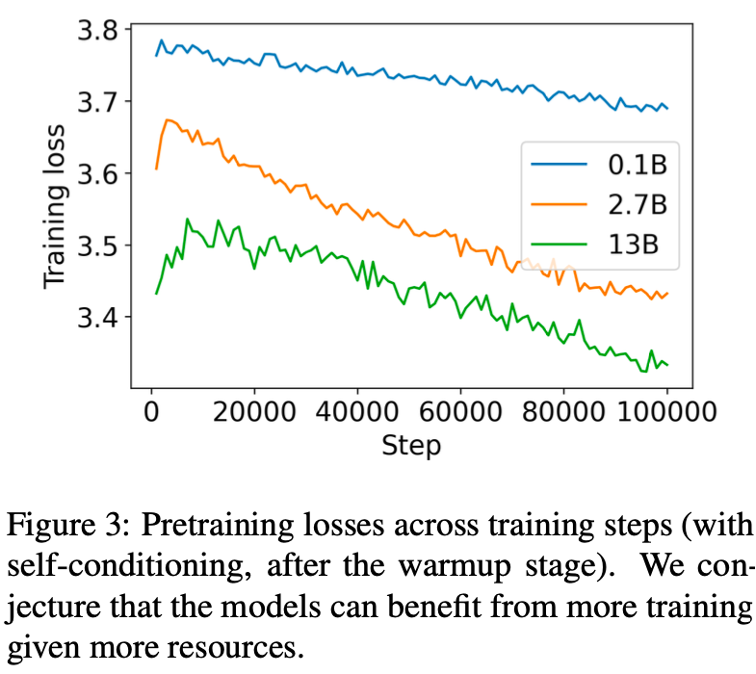
这张图是作者在训练时尝试了三种不同的参数规模,且从图中可看出来,13B的模型loss值还比较高,模型受限于计算资源没有完成收敛。而后面的实验结果,也全是在模型未完全收敛的情况下进行对比的。
Spotlight1: Chat-style instruction finetuning
这篇文章相对比与之前的diffusion nlp结合的文章,我觉得他的亮点首先是chat-style 的instruction finetuning的方式。很好的结合了当前的热点,也没有回避大语言模型在当前NLP领域的引领地位。同时尝试在diffusionNLP模型中进行了对话的形式。
作者使用dolly dataset进行finetune,他也是alpaca和vicuna模型用来训练的数据集。对于ssd-2 finetune性能评价,使用了GPT-4模型。从实验结果表中可以看出,SSD-2模型在同规模自回归模型中具有竞争力。
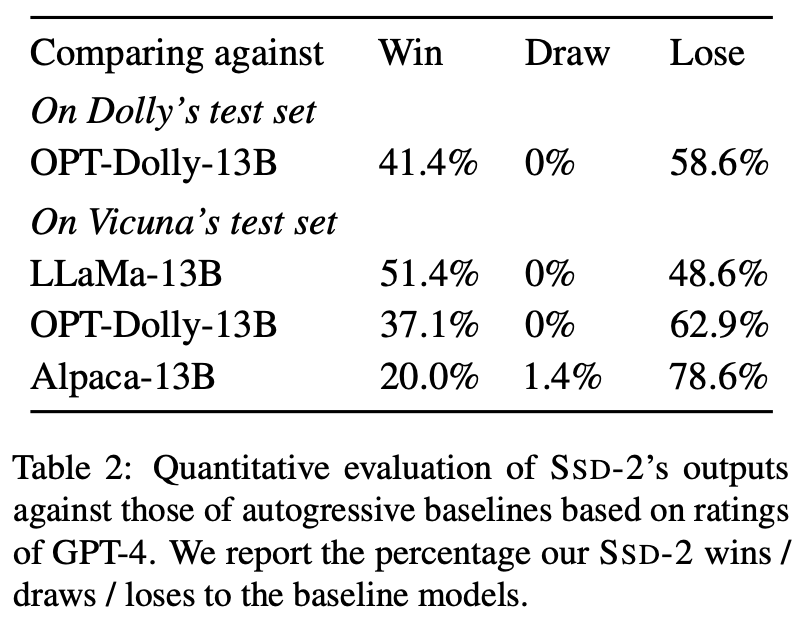
且作者指出,使用的对比模型相比于SSD-2,使用了更多数据集进行训练,但SSD-2仍然在胜过某些模型。因此作者认为,如果ssd-2使用相同规模的模型参数进行训练,可能能够表现的更好。
Spotlight2: Inference-time collaboration
第二个亮点 则考虑了用户交互的过程。现在的大语言模型是比较通用的,但用户会更偏向于使用结合自身情况的模型,而SSD-2则考虑了这种情况。
首先是问题的set up:
- Purpose: to customize the system with their own data.
- Setup:
- A core model \(θ_{core}\) : good at general-domain instruction following.
- A user model \(θ_{user}\) : computationally friendly for a typical user to run on their personal device or a cloud device to their control.
- A prompting instruction \(w_{inst}\) both the models have access to.
- A expert data \(D_user\) only the user model and not the core model has access to.
Core model擅长于通用领域的指令回答。User model 对于用户更加友好,适用于个人设备或者云设备。Prompting instruction 和 expert data, 即用户个人数据
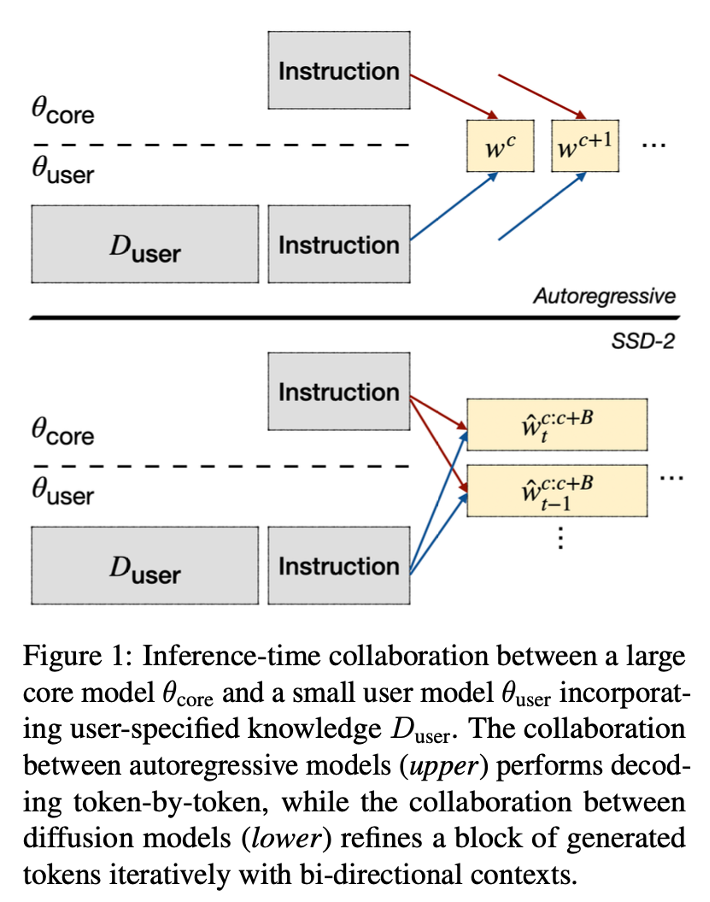
During inference:
- \(θ_{core}\) only takes in the prompt \(w_{inst}\), \(f_{θ_{core}} (w_{inst})\).
- the user model takes in both the user expert data and the instruction as input \(f_{θ_{user}} (D_{user}, w_{inst})\).
在inference 阶段Core model 使用prompt作为输入,user model把expert data和prompt同时作为输入。不同于autoregressive models,diffusion based models可以使用双向上下文迭代优化生成的令牌块。
结果也是使用GPT3.5进行评分。可以看出,提出的SSD-2模型在collaboration协作的setting下面,有一定的效果。
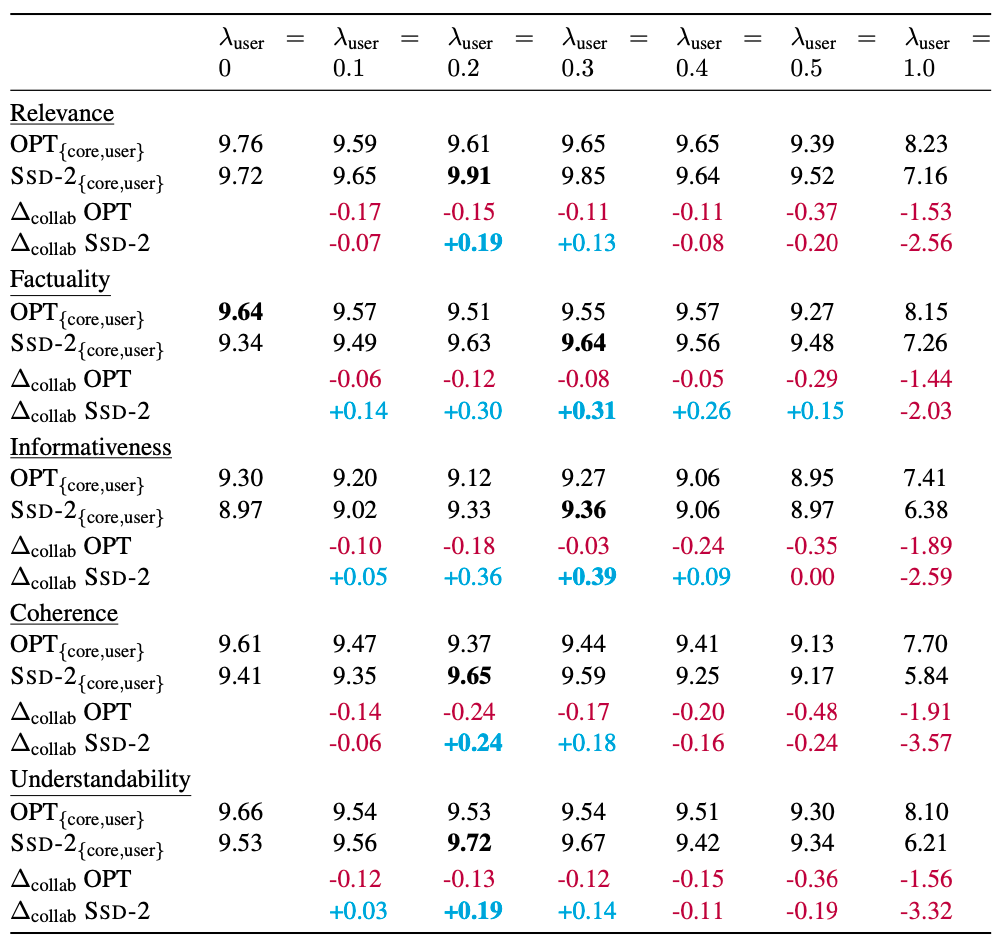
3. Different applications of diffusion models in NLP
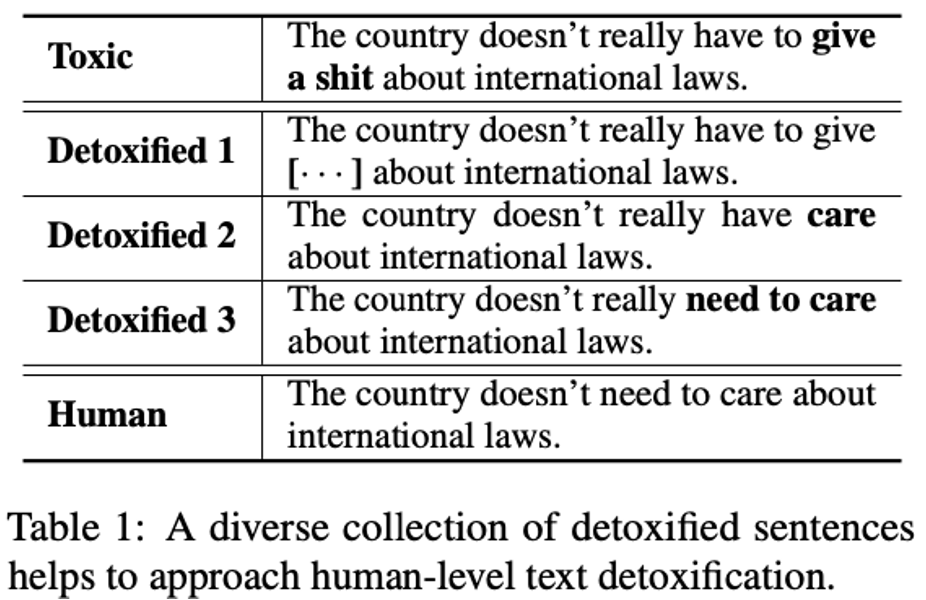
第三个我想提及的diffusion nlp发展方向是,除了文本生成外的应用方向。 DiffuDetox是ACL2023的文章,把diffusion和nlp结合的模型应用到了文本去毒里。可以理解为去除一些粗俗不适的文本,如table1所示。
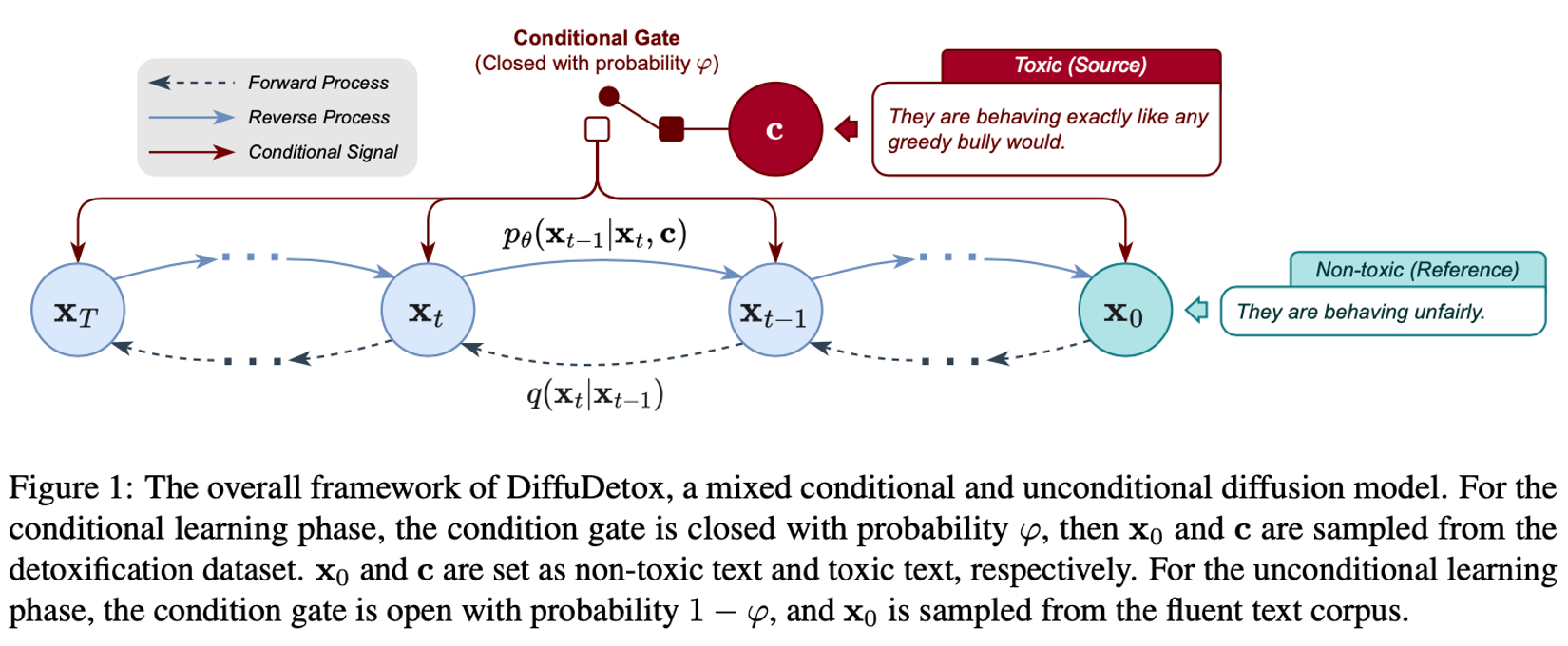
而diffudetox使用了混合的有条件和无条件的diffusion model。其中条件diffusion model把toxic text作为条件输入,而无条件的模型的训练是为了还原输入的文本内容。
DiffuDetox:
- a mixed conditional and unconditional diffusion model for text detoxification.
- The conditional model takes toxic text as the condition and reduces its toxicity, yielding a diverse set of detoxified sentences.
- The unconditional model is trained to recover the input text, which allows the introduction of additional fluent text for training and thus ensures text fluency.
框架如图所示:
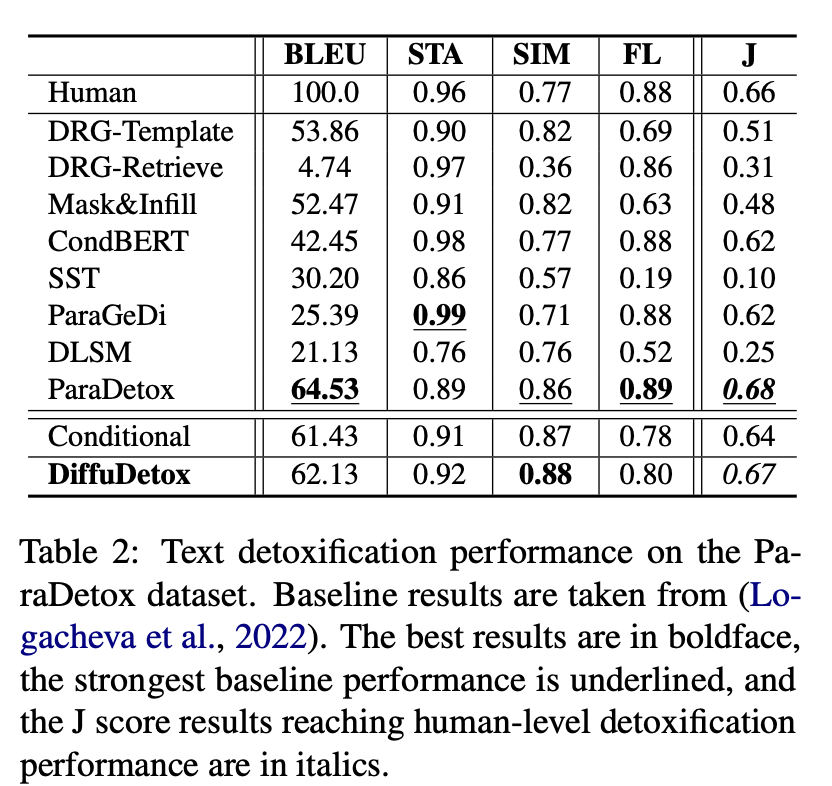
然后是实验结果,也能看出这种方法会大部份baseline好,甚至在一些指标上达到了sota性能。
4. Novel text generation ways
最后一个可能可以进行下去的方向是提出一些新颖的与diffusion model结合的文本生成方式。去年我在ICLR2023上看到了一种语言模型的生成方式: Language Modelling with Pixels,是使用像素(图像)的方式对文本进行建模,再生成。其框架如下所示。使用这种方法的好处是,对于拼写错误攻击和语言代码切换更健壮。
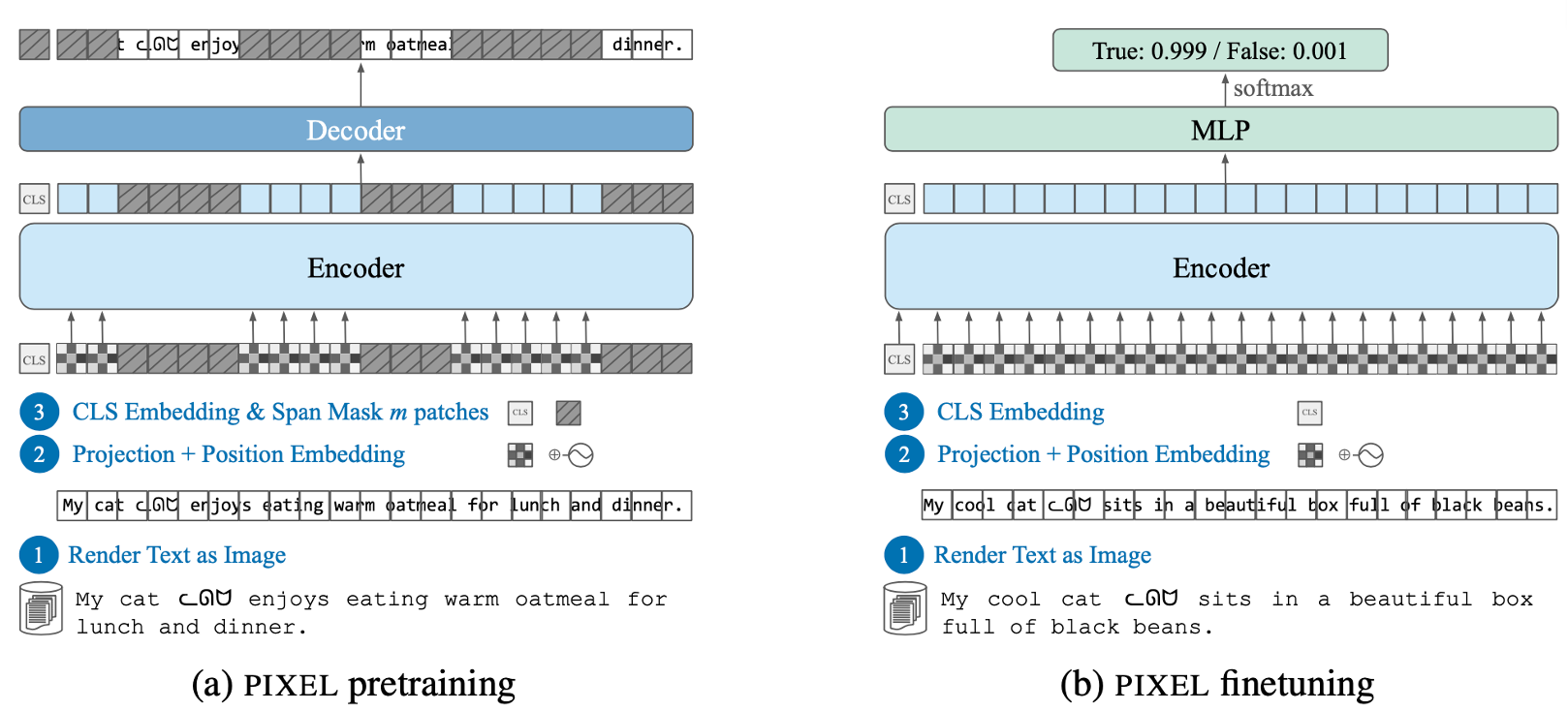
然后我在进行diffusion model和nlp检索时,也看到了引用了这篇文章的一个paper: GlyphDiffusion: Text Generation Is Also Image Generation,是今年4月份挂在arxiv上的文章,它的建模方式跟ICLR那篇文章是一样。
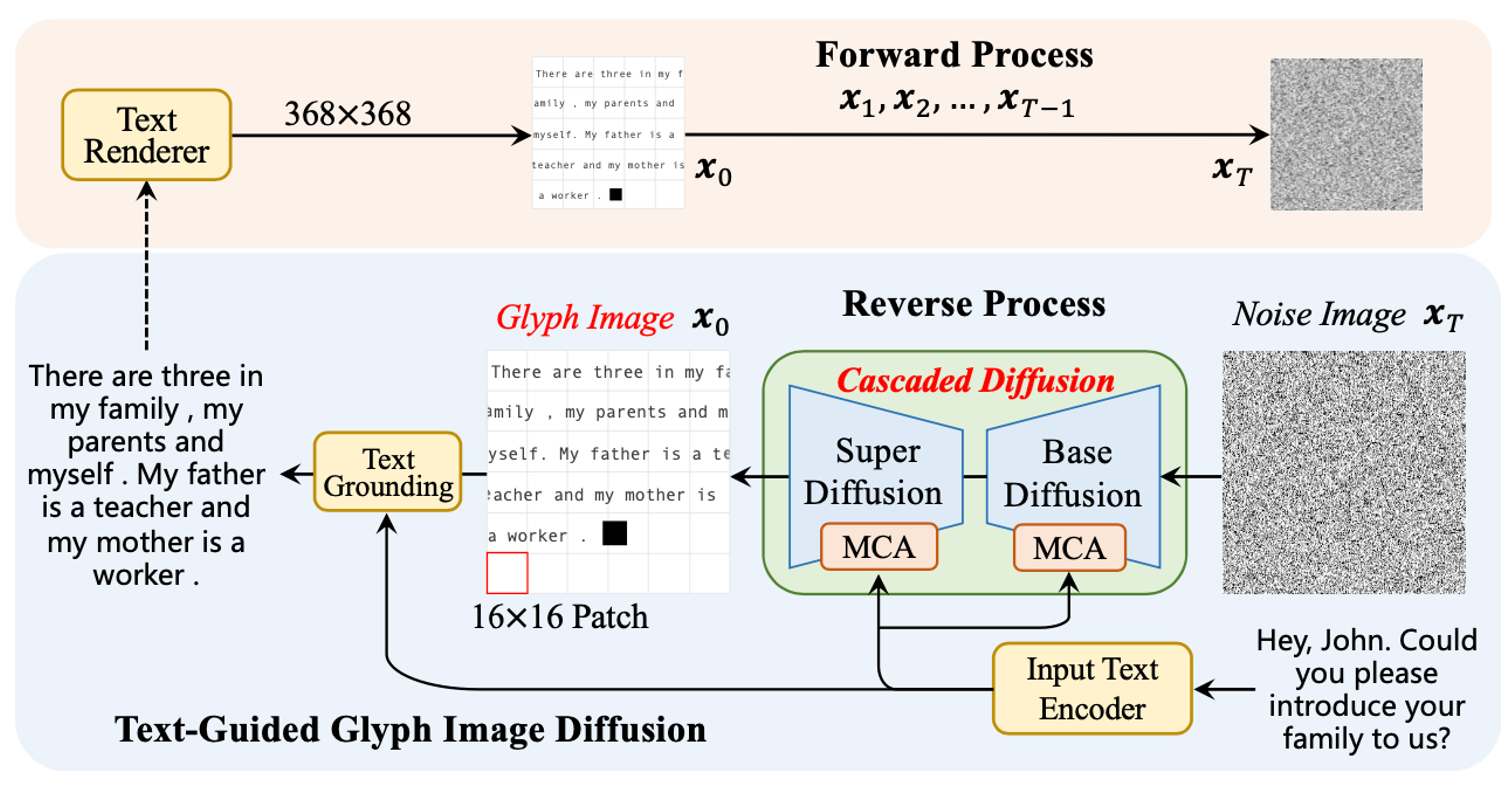
实验结果如下:
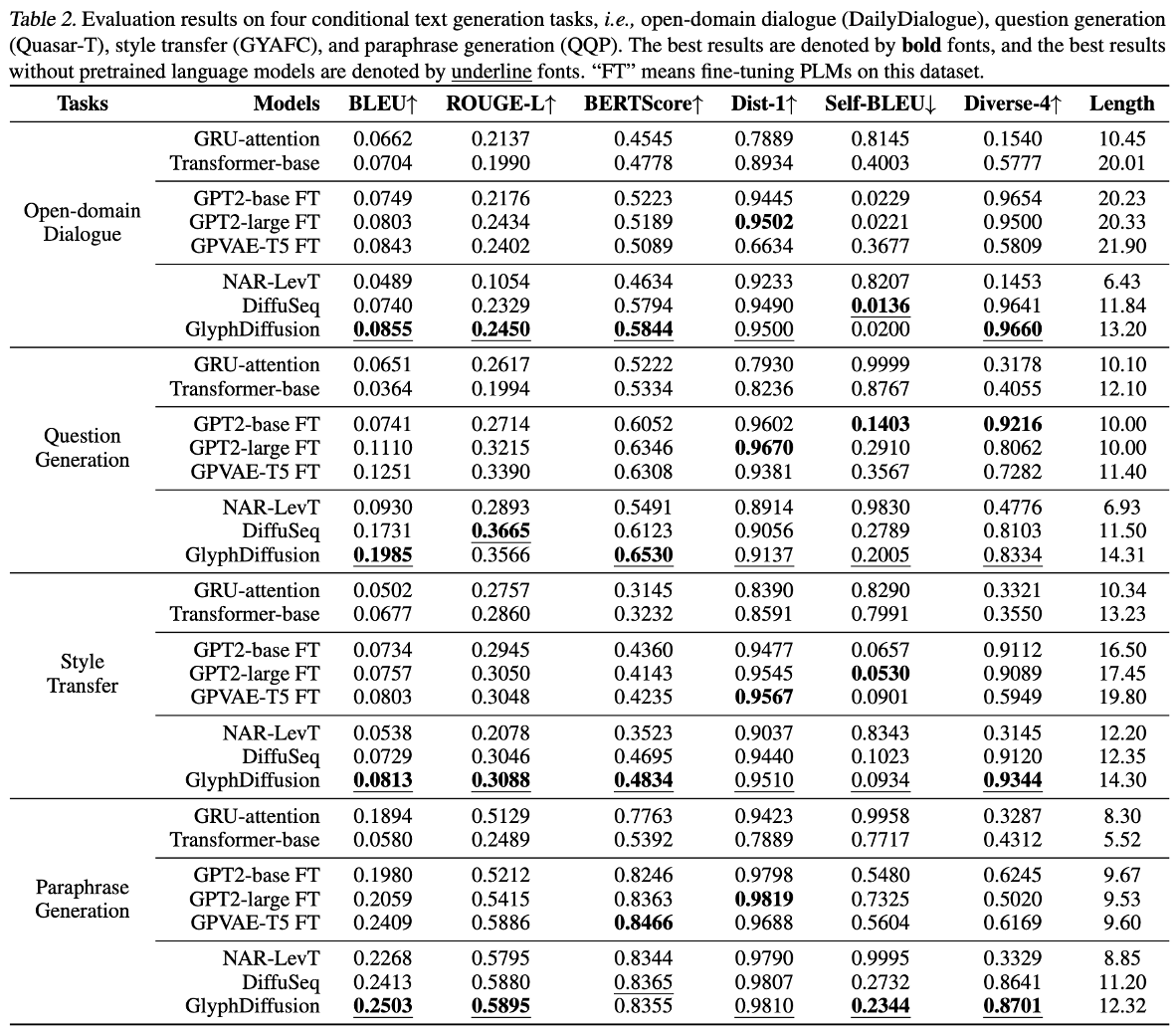
同时,这篇文章比起对文本diffusion有一个好处是,可以直接把在图像diffusion领域发展的先进知识引入进来。结果如下所示,作者认为使用这种建模方法能够产生更diverse的文本,同时减少重复和错误拼写。
结论
这个内容是我Date:231023做组会时的汇报,主要是结合了前段时间的工作展开介绍。写这篇Blog时,距离work DDL只有4天,所以算是Diffusion + NLP 的一篇收尾汇总啦。如果不出意外,此系列几乎不更新了。
算是第一篇内容Blog完结撒花 🎉 ?